Quantum Pipeline¶

![]()




![]()

Overview¶
Quantum Pipeline is a framework for running quantum algorithms. Currently, only the Variational Quantum Eigensolver (VQE) is implemented. It combines quantum and classical computing to estimate the ground-state energy of molecular systems.
The framework handles algorithm orchestration, parametrization, monitoring, and data visualization. Simulation results can be streamed via Apache Kafka for real-time processing and transformed into ML features using Apache Spark.
It started as a Bachelor of Engineering thesis project at the DSW University of Lower Silesia and is continued as a Master of Engineering thesis project. It is still a work in progress.
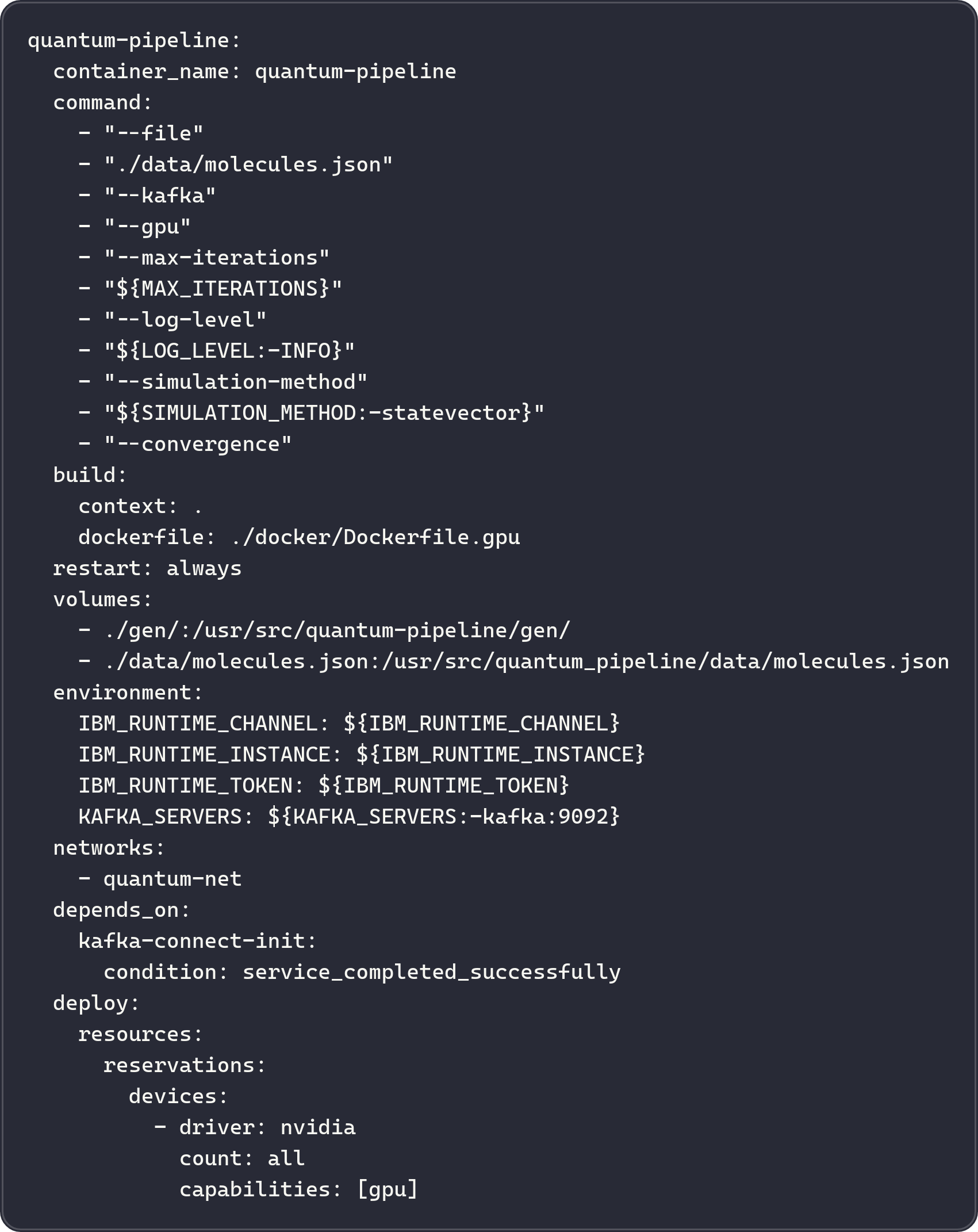
Quick Links¶
-
Getting Started
Install Quantum Pipeline and run your first VQE simulation in minutes
-
Configuration
Learn about optimizers, ansatz types, initialization strategies, and parameter tuning
-
Architecture
Understand the system design and data flow
-
Deployment
Deploy with Docker, enable GPU acceleration, configure environments
Links related to the project¶
- GitHub: straightchlorine/quantum-pipeline
- Codeberg (mirror): piotrkrzysztof/quantum-pipeline
- Docker Hub: straightchlorine/quantum-pipeline
- PyPI: quantum-pipeline
- Issues: Report bugs or request features
Thesis project
This project began as a Bachelor of Engineering thesis at the DSW University of Lower Silesia, focusing on GPU-accelerated quantum simulation and data engineering for quantum computing workflows. It is continued as a Master of Engineering thesis.