Spark Processing¶
Apache Spark 4.0.2 transforms raw VQE simulation results into structured ML feature tables. Processing is batch-oriented and incremental - only new data since the last run is processed.
For how Spark fits into the overall architecture, see System Design. For feature table schemas, see System Design - Feature Tables.
Cluster Architecture¶
The cluster runs in standalone master-worker mode via a custom Docker image
built from
docker/Dockerfile.spark
(based on apache/spark:4.0.2-python3 with Python upgraded to 3.12 to match
the Airflow driver).
| Node | Role | Resources |
|---|---|---|
spark-master |
Coordinator | 1 GB RAM limit |
spark-worker |
Executor | 3 GB container limit, 2 GB Spark worker memory, 2 cores |
Worker memory and cores are configurable via SPARK_WORKER_MEMORY and
SPARK_WORKER_CORES in
compose/docker-compose.ml.yaml.
Key details:
- Workers register with the master at
spark://spark-master:7077 - Airflow submits jobs via
SparkSubmitOperator - Workers access Garage through the S3A filesystem connector
- Configuration is loaded from
compose/spark-defaults.confmounted into containers - S3 credentials are passed via
AWS_ACCESS_KEY_IDandAWS_SECRET_ACCESS_KEYenvironment variables - JAR dependencies (Iceberg runtime, Hadoop AWS, Spark Avro) are resolved via
Maven/Ivy at startup and cached in the
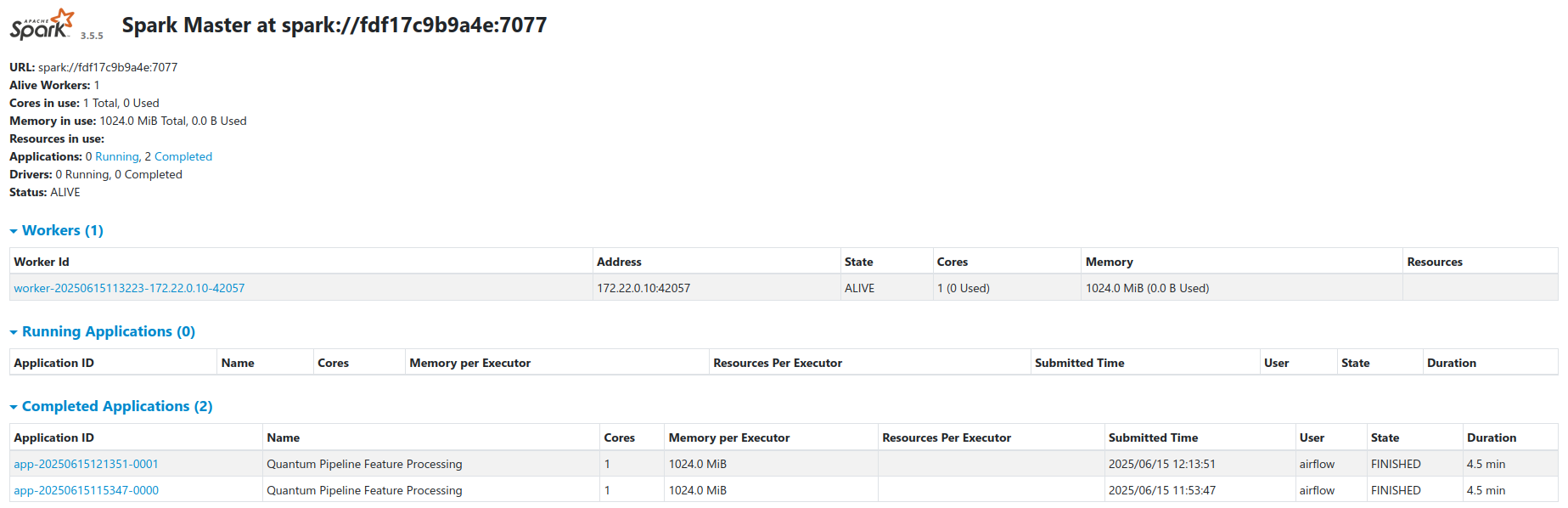
spark-ivy-cachevolume - Spark Web UI is available at port
8080on the master node (published to host port8080)
Spark Configuration¶
All Spark scripts use a shared session factory
(docker/airflow/common/spark_factory.py)
that creates a SparkSession with only the app name. All other settings come
from spark-defaults.conf:
| Setting | Value |
|---|---|
| S3A endpoint | http://garage:3901, path-style access, fast upload |
| Iceberg catalog | quantum_catalog, Hadoop type, warehouse at s3a://features/warehouse/ |
| Serialization | KryoSerializer |
| Memory | 1 GB driver, 1536 MB executor, 8 shuffle partitions |
| JARs | iceberg-spark-runtime-4.0_2.13:1.10.1, hadoop-aws:3.4.1, spark-avro_2.13:4.0.2 |
Default S3 paths from
common/pipeline_config.py:
| Path | Default |
|---|---|
| Experiment bucket | s3a://raw-results/experiments/ |
| Feature warehouse | s3a://features/warehouse/ |
Feature Engineering Pipeline¶
The processing script
quantum_incremental_processing.py
follows a 6-step workflow:
- Create Spark session - via the shared factory
- Initialize Iceberg metadata - create catalog/database on first run, load existing metadata on subsequent runs
- Filter new data - join against existing Iceberg table keys using a
marker-column approach (see
identify_new_records()) - Extract features -
transform_quantum_data()flattens nested VQE fields into 9 specialized tables with metadata columns (experiment_id,processing_timestamp,processing_date,processing_batch_id) - Write Parquet to Garage - via
process_incremental_data(), creating tables on first run, appending only new records on subsequent runs - Tag Iceberg snapshots - version tags (
v_{batch_id}orv_incr_{batch_id}) for time-travel queries
Feature Tables¶
Base Feature Tables (9 tables)¶
Produced by the quantum_feature_processing DAG and stored under
quantum_catalog.quantum_features. For the full schema of all 9 tables, see
System Design - Feature Tables.
| Table | Key Columns | Partition Columns |
|---|---|---|
molecules |
experiment_id, molecule_id | processing_date |
ansatz_info |
experiment_id, molecule_id | processing_date, basis_set |
performance_metrics |
experiment_id, molecule_id, basis_set | processing_date, basis_set |
vqe_results |
experiment_id, molecule_id, basis_set | processing_date, basis_set, backend |
initial_parameters |
parameter_id | processing_date, basis_set |
optimal_parameters |
parameter_id | processing_date, basis_set |
vqe_iterations |
iteration_id | processing_date, basis_set, backend |
iteration_parameters |
parameter_id | processing_date, basis_set |
hamiltonian_terms |
term_id | processing_date, basis_set, backend |
ML Feature Tables (2 tables)¶
Produced by the quantum_ml_feature_processing DAG
(quantum_ml_feature_processing.py).
These join and aggregate the 9 base tables into ML-ready datasets.
| Table | Purpose |
|---|---|
ml_iteration_features |
Per-iteration feature vectors combining energy data with rolling statistics, parameter snapshots, and molecular context |
ml_run_summary |
Per-run aggregate features summarizing convergence metrics, timing, and molecule-level data |
Incremental Processing¶
Each run processes only new data:
- List current files in the Garage experiments bucket
- Check Iceberg snapshots for already-processed file paths
- Compute delta - new files not yet processed
- Process delta only - read, transform, append to feature tables
- Update snapshot - new Iceberg snapshot records the processed set
The deduplication logic is in
identify_new_records()
and the write logic in
process_incremental_data().
Related Documentation¶
- System Design - Full architecture and feature table schemas
- Airflow Orchestration - Spark job scheduling
- Iceberg Storage - Table format and snapshots
- Kafka Streaming - Raw data ingestion