Examples¶
Usage examples for common Quantum Pipeline workflows, from simple simulations to full data pipeline integration.
Simple H\(_2\) Simulation¶
Run a minimal VQE simulation for a hydrogen molecule to verify the pipeline works.
quantum-pipeline \
-f data/molecules.json \
--basis sto3g \
--max-iterations 50 \
--optimizer L-BFGS-B
The sto3g basis set is the smallest and fastest, good for quick tests. H\(_2\) maps to 4 qubits with sto3g, making it a simple test case. The expected ground state energy for H\(_2\) at 0.74 Angstrom bond length is approximately -1.137 Hartree.
Multi-Molecule Batch Processing¶
Process multiple molecules in a single run using the same simulation configuration. The pipeline processes each molecule sequentially - for each one it generates the Hamiltonian, maps to qubits, and runs VQE.
The molecule data file is a JSON array. See the included data/molecules.json for the format.
| Field | Type | Description |
|---|---|---|
symbols |
string array | Atom symbols (e.g. ["H", "H"]) |
coords |
float array | 3D coordinates per atom |
multiplicity |
int | Spin multiplicity |
charge |
int | Net charge |
units |
string | Distance unit (e.g. "angstrom") |
masses |
float array | Atomic masses |
quantum-pipeline \
-f data/molecules.json \
--basis sto3g \
--max-iterations 100 \
--optimizer L-BFGS-B \
--ansatz-reps 2 \
--shots 1024 \
--report
Use --report to generate a PDF report in gen/ with molecular structure, convergence plots, and Hamiltonian coefficients. Ansatz circuit diagrams are saved separately in gen/graphs/ (example, decomposed). Larger molecules need more qubits: H\(_2\) uses 4, LiH uses 12, H\(_2\)O uses 14 (with sto3g). Processing time varies accordingly.
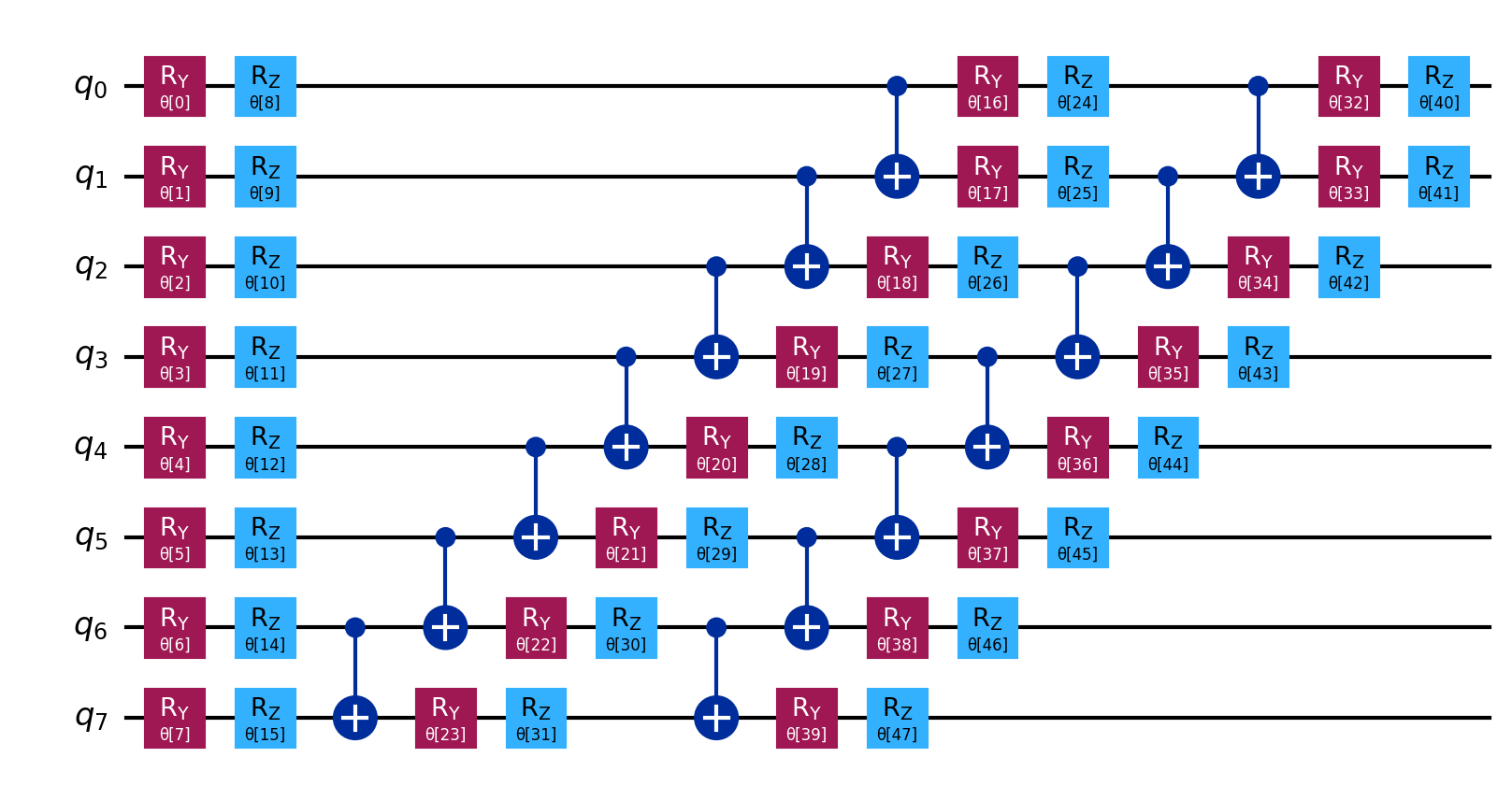{kind=link}
{kind=link}
GPU-Accelerated Simulation¶
Run a higher-accuracy simulation using GPU acceleration with the cc-pvdz basis set.
quantum-pipeline \
-f data/molecules.json \
--basis cc-pvdz \
--convergence \
--threshold 1e-8 \
--optimizer L-BFGS-B \
--init-strategy hf \
--ansatz-reps 5 \
--shots 4096 \
--optimization-level 3 \
--gpu \
--simulation-method statevector \
--report
GPU acceleration offloads statevector operations to the NVIDIA GPU. The cc-pvdz basis set provides higher accuracy but needs significantly more qubits (e.g. 48 for H\(_2\)O). Convergence mode runs until the energy change falls below the threshold.
The --init-strategy hf flag pre-optimizes parameters using Hartree-Fock data, which helps avoid local minima that are common with cc-pvdz. This strategy only works with the EfficientSU2 ansatz - using it with other ansatze falls back to random initialization.
GPU performance
In thesis benchmarks (GTX 1060/1050 Ti, H\(_2\) molecule), GPU acceleration provided 1.7-4x speedup depending on basis set and circuit size. The cc-pvdz basis set generates many more qubits than sto3g, so ensure you have enough GPU memory (6+ GB recommended). For circuits exceeding GPU memory, consider --simulation-method tensor_network.
Full Data Pipeline with Kafka¶
Run a VQE simulation with Kafka streaming enabled, demonstrating the complete data pipeline from simulation to storage.
Start the infrastructure stack first using Docker Compose. See the compose/ directory and the Docker Compose deployment guide for available configurations.
quantum-pipeline \
-f data/molecules.json \
--basis sto3g \
--max-iterations 150 \
--optimizer L-BFGS-B \
--gpu \
--simulation-method statevector \
--kafka \
--servers kafka:9092 \
--topic experiment.vqe \
--acks all \
--retries 3
What happens:
- The VQE simulation runs with GPU acceleration.
- Results are serialized using Avro format and the schema is registered with the Schema Registry.
- The serialized result is published to the Kafka topic.
- Redpanda Connect picks up the message and writes it to Garage (S3-compatible storage) as an Avro file.
The --kafka flag is required to enable streaming. Without it, other Kafka parameters are ignored. After Redpanda Connect transfers data to Garage, Apache Airflow can trigger Spark processing for feature engineering.
Convergence-Based Optimization¶
Use convergence-based stopping instead of a fixed iteration count, allowing the optimizer to run until the energy stabilizes.
quantum-pipeline \
-f data/molecules.json \
--basis sto3g \
--convergence \
--threshold 1e-6 \
--optimizer L-BFGS-B \
--shots 2048
The optimizer runs until the energy change between consecutive iterations falls below the threshold. For well-behaved problems (H\(_2\) with L-BFGS-B), convergence typically occurs within 30-80 iterations. For more complex molecules, it may require hundreds.
Threshold guidelines¶
| Threshold | Precision level | Typical use case |
|---|---|---|
1.6e-3 |
Chemical accuracy (~1 kcal/mol) | Fast prototyping |
1e-6 |
Standard (1 microHartree) | General runs |
1e-8 |
High precision (10 nanoHartree) | Publication-quality research |
Convergence mode (--convergence) and fixed iterations (--max-iterations) are mutually exclusive at the OptimizerConfig level. If --convergence is enabled and --max-iterations is left at the default, the entry point sets max_iterations to None. Passing both non-default values raises a ValueError.
For L-BFGS-B, the convergence threshold is passed as ftol and gtol in the options dict. For COBYLA and other optimizers, it is passed as the global tol parameter to scipy.optimize.minimize.
Configuration Save and Load¶
Save a simulation configuration for reproducibility and reload it later.
Save configuration¶
Adding --dump saves the run configuration as a JSON file in run_configs/. The filename encodes the molecule file, basis, optimizer, backend, and date (for example molecules-cc-pvdz-L-BFGS-B-local-20250615.json).
quantum-pipeline \
-f data/molecules.json \
--basis cc-pvdz \
--convergence \
--threshold 1e-6 \
--optimizer L-BFGS-B \
--ansatz RealAmplitudes \
--init-strategy hf \
--ansatz-reps 2 \
--shots 2048 \
--gpu \
--simulation-method statevector \
--dump
Load a saved configuration¶
--dump and --load are mutually exclusive. Note that --load currently only reads and validates the file: its values are not merged back into the run, which still uses the CLI flags and defaults. Treat a dumped config as a record of the settings a run used rather than a way to replay it.
Programmatic Usage¶
The pipeline can also be used as a Python library through the VQERunner class. It accepts the same parameters as the CLI but as constructor arguments, and returns VQEDecoratedResult objects containing the full simulation data, including per-iteration energy values.
Backend, Kafka producer, and security settings can be passed as BackendConfig, ProducerConfig, and SecurityConfig objects respectively.
Note that a few VQERunner constructor defaults differ from the CLI defaults: the optimizer defaults to COBYLA (CLI: L-BFGS-B) and ansatz_reps defaults to 3 (CLI: 2). Pass these explicitly when you want a run to match its CLI equivalent.
This is useful for parameter sweeps, automated benchmarks, and integration with analysis notebooks.
Full Stack Experiment¶
Run experiments with the full ML data pipeline. Copy the .env.ml.example file and customize it for your system:
Start the full stack using Docker Compose (see the Docker Compose deployment guide), then monitor progress through container logs and nvidia-smi.
Ansatz and Init Strategy Comparison¶
Compare different ansatz types and initialization strategies to find the best combination for a given molecule.
# RealAmplitudes with random init
quantum-pipeline \
-f data/molecules.json \
--basis sto3g \
--max-iterations 100 \
--optimizer L-BFGS-B \
--ansatz RealAmplitudes \
--init-strategy random \
--seed 42 \
--report
# EfficientSU2 with Hartree-Fock init
quantum-pipeline \
-f data/molecules.json \
--basis cc-pvdz \
--max-iterations 200 \
--optimizer L-BFGS-B \
--ansatz EfficientSU2 \
--init-strategy hf \
--seed 42 \
--report
# ExcitationPreserving ansatz
quantum-pipeline \
-f data/molecules.json \
--basis sto3g \
--max-iterations 100 \
--optimizer L-BFGS-B \
--ansatz ExcitationPreserving \
--ansatz-reps 3 \
--report
The --seed flag ensures reproducible results across runs with the same configuration. The --init-strategy hf flag only works with EfficientSU2 - using it with other ansatze falls back to random initialization. Use --report to generate convergence plots for visual comparison.
The three supported ansatze are:
| Ansatz | Description |
|---|---|
EfficientSU2 |
Default. General-purpose with Ry and Rz rotation gates and CNOT entanglement. |
RealAmplitudes |
Uses only real-valued Ry rotation gates. Suitable for Hamiltonians with real coefficients. |
ExcitationPreserving |
Preserves particle number, which can be physically motivated for molecular systems. |
Quick reference¶
| Example | Use case | Key flags |
|---|---|---|
| Simple H\(_2\) | Installation test | --basis sto3g --max-iterations 50 |
| Batch Processing | Multi-molecule runs | --report |
| GPU Research | High-accuracy GPU | --gpu --basis cc-pvdz --init-strategy hf |
| Data Pipeline | Kafka streaming | --kafka --servers kafka:9092 |
| Convergence | Adaptive stopping | --convergence --threshold 1e-6 |
| Save/Load | Record run settings | --dump / --load |
| Python API | Programmatic usage | VQERunner class |
| Full Stack | Full ML pipeline | .env.ml.example |
| Ansatz/Init | Ansatz comparison | --ansatz --init-strategy |
Next steps¶
- Configuration Reference for detailed parameter documentation
- Optimizers for optimizer choices
- Simulation Methods for backend selection
- Docker Compose for deployment